Effortless Email Forwarding
Easily send & receive emails for your custom domain.
Generous free tier. Rock-solid infrastructure. World-class support.
No credit card required, full privacy protection

Trusted by leading companies and organizations worldwide.
Clean Simple Interface
Easily manage your email forwarding with zero clutter.
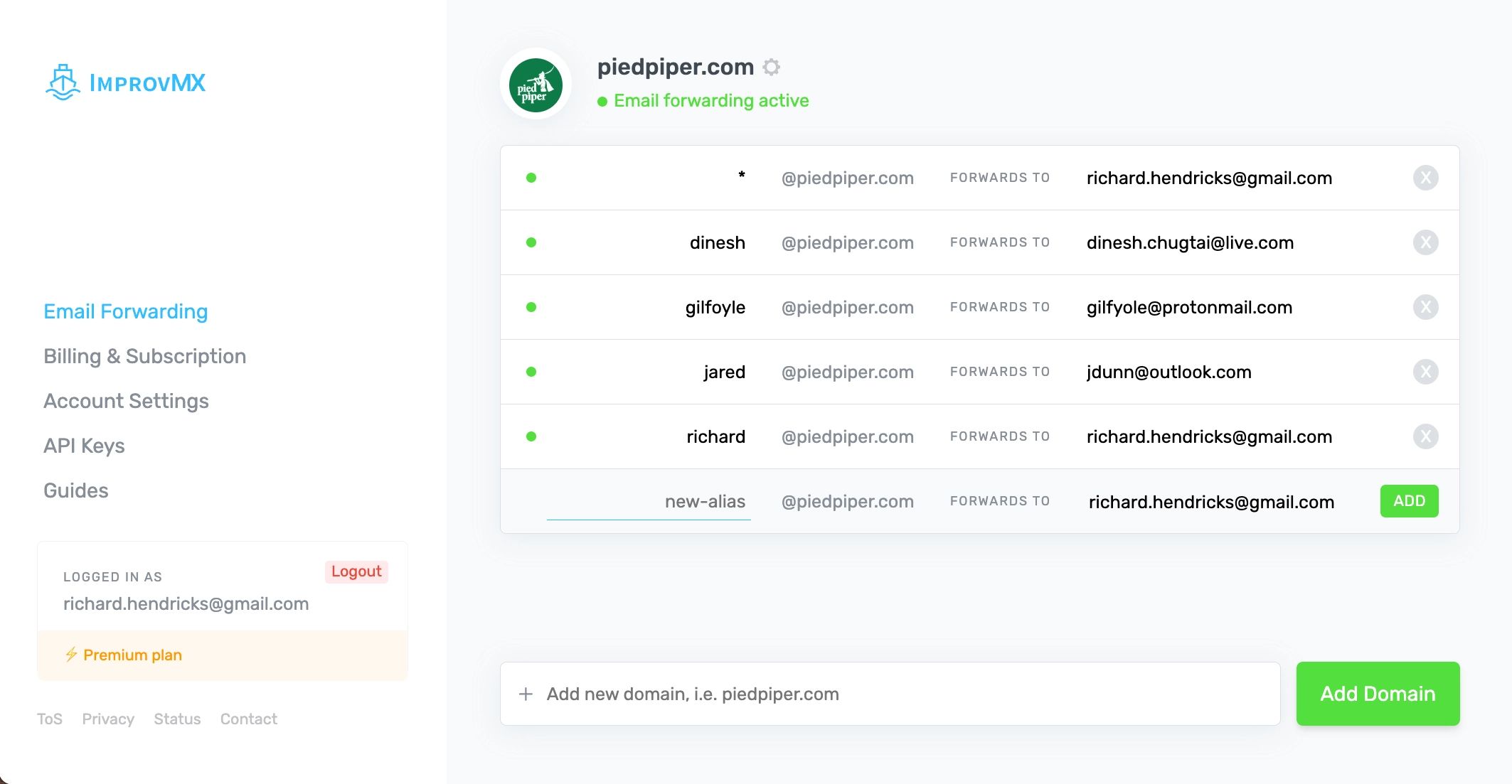
Complete Email Toolkit
Everything you need for advanced email management.
SMTP Email Sending
Use our SMTP service to send emails from your custom domain. Make your emails appear consistent and professional!
Fast & Reliable
The average email forwards in under 5s. We have a 99.99% SLA, and we deliver hundreds of thousands of emails per day! Learn more.
Advanced Email Routing
Set up catch-all email aliases, regex aliases, or fully customizable routing rules to control incoming email routing.
Redirect to Multiple Addresses
One alias can fan out forward to multiple destinations. You can also blackhole to “null”, or send all emails to a webhook!
Email logs
An email didn’t arrive? We’ve built email logs to help you troubleshoot what’s going on. See what we log.
API Interface
Programatically interact with ImprovMX! Create domains, set aliases, view logs, and more, all via secure API key access.
We don’t read emails.
We don’t sell data.
ImprovMX is fully compliant with GDPR,
the most stringent data protection laws.
We do not read your emails and never will.
Set your privacy level to control exactly what we log.
They Forward With Us
Over 200,000 users and many of the world’s leading organizations trust ImprovMX to forward emails for their business, internal tools and side projects.
If you're looking for simple email forwarding, ImprovMX is the place to go. Simple, to the point, and does what it promises. I run all my 17 products with them.



Fast Reliable Delivery
We’re like you, we hate delayed or missing emails.
Our average email forwards in under 5 seconds.
See our Security & Reliability Philosophy.
Gmail
N/A
Outlook
N/A
Apple
N/A
Yahoo
N/A
We have a 99.99% SLA over the past 90 days.
We serve millions of emails daily.